Utilize AutoSort in chronic recordings#
In this tutorial, we demonstrate how to utilize a trained AutoSort model with late-stage recordings
For explanatory data analysis, we provide one days recording on 0319, which can be downloaded here.
[1]:
from autosort_neuron import *
import warnings
warnings.filterwarnings("ignore")
/n/holystore01/LABS/jialiu_lab/Users/yichunhe/AutoSort/autosort_neuron/sorting.py:19: DeprecationWarning: The 'toolkit' module is deprecated. Use spikeinterface.preprocessing/postptocessing/qualitymetrics instead
import spikeinterface.toolkit as st
[<torch.cuda.device object at 0x14da06da3310>]
First, we set electrode probe of the new recording data.
[2]:
positions=np.array([
[150, 250], ### electrode 1
[150,200], ### electrode 2
[50, 0], ### electrode 3
[50, 50],
[50, 100],
[0, 100],
[0, 50],
[0, 0],
[650, 0],
[650, 50],
[650, 100],
[600, 100],
[600, 50],
[600, 0],
[500, 200],
[500, 250],
[500, 300],
[450, 300],
[450, 250],
[450, 200],
[350, 400],
[350, 450],
[350, 500],
[300, 500],
[300, 450],
[300, 400],
[200, 200],
[200, 250],
[200, 300],
[150, 300]
])
mesh_probe = create_mesh_probe(positions=positions,num_all_channels=positions.shape[0])
### raw data path
raw_data_path = './raw_data/'
### file folder name to read
date_id_all=['0319']
Load raw data recording from Intan system
[3]:
for i in date_id_all:
save_folder_name = i
data_folder_all = f"./processed_data/Ephys_concat_{save_folder_name}/"
if os.path.exists(data_folder_all) == False:
_, _ = read_data_folder(
data_folder_all,
[i],
raw_data_path,
mesh_probe,
)
processing: 0319
./raw_data/0319/0319_230126_211840.rhd
Reading Intan Technologies RHD2000 Data File, Version 3.0
n signal groups 11
Found 32 amplifier channels.
Found 3 auxiliary input channels.
Found 0 supply voltage channels.
Found 0 board ADC channels.
Found 1 board digital input channel.
Found 0 board digital output channels.
Found 0 temperature sensors channels.
File contains 990.848 seconds of data. Amplifiers were sampled at 10.00 kS/s.
Allocating memory for data...
Reading data from file...
10% done...
20% done...
30% done...
40% done...
50% done...
60% done...
70% done...
80% done...
90% done...
Parsing data...
No missing timestamps in data.
Done! Elapsed time: 7.0 seconds
--saving to: ./processed_data/Ephys_0319/
write_binary_recording with n_jobs = 1 and chunk_size = None
saving to: ./processed_data/Ephys_concat_0319/
write_binary_recording with n_jobs = 1 and chunk_size = None
BinaryFolderRecording: 30 channels - 1 segments - 10.0kHz - 990.848s
Num. channels = 30
Sampling frequency = 10000 Hz
Num. timepoints seg0= 1
Generate input of AutoSort.
[4]:
save_pth = './AutoSort_data/'
day_pth = './processed_data/'
raw_data_path = './raw_data/'
freq_max=3000
freq_min=300
left_sample=10
right_sample=20
[5]:
generate_autosort_input(date_id_all,
raw_data_path,
save_pth,
day_pth,
left_sample,
right_sample,
freq_min,
freq_max,
mesh_probe,
mode='test'
)
### 0319
### 1. load raw data
### 2. detect spikes
### 5. find corresponding waveform
100%|██████████| 30/30 [00:31<00:00, 1.06s/it]
### 6. save output
Apply AutoSort
[6]:
### group ID of each electrode 1,2,3...
electrode_group=[1, 1, 0, 0, 0, 0, 0, 0, 4, 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1]
electrode_position=np.hstack([positions,np.array(electrode_group).reshape(-1,1)])
[7]:
args=config()
args.day_id_str=['0310','0319'] ### all days
args.cluster_path='./AutoSort_data/' ### path of input data
args.set_time=0 ### set 0411 data as training data
args.test_time=[1] ### set 0420 data as testing data
args.group=np.arange(30) ### all electrodes
args.samplepoints=left_sample+right_sample ### 30 points for each waveform
args.sensor_positions_all=electrode_position
args.mode='test'
[8]:
run(args)
---------------------------------- SEED ALL ----------------------------------
Seed Num : 0
---------------------------------- SEED ALL ----------------------------------
<autosort_neuron.config.config object at 0x14da06d99250>
pred_location (1389499, 3)
pred_location (807187, 3)
AutoSort results are saved in ./model_save/train_day0310_0/offline_results/[test date]/.
We read the results through read_AutoSort_data function
[9]:
results_data_path = f'./AutoSort_data/model_save/train_day0310_0/offline_result/0319/'
extremum_channels_ids_pth='./processed_data/Ephys_concat_0310_0315/mountainsort/extremum_channels_ids.csv'
(sorting,
trial_start,
trial_end,
cont_trigger_all_all,
recording_cmr) = read_AutoSort_data('0319',
day_pth,
results_data_path,
save_pth=save_pth,
extremum_channels_ids_pth=extremum_channels_ids_pth
)
0319 there are 28 trials at an interval of: 19383
origin spike num:807187
noise prediction after spike num:210633
channel correspondence after spike num:152291
label prob spike num:133807
Extract waveforms
[10]:
waveform_folder = results_data_path+ 'waveforms'
# shutil.rmtree(waveform_folder)
we = spikeinterface.extract_waveforms(recording_cmr, sorting, waveform_folder,
load_if_exists=True,
ms_before=1, ms_after=2., max_spikes_per_unit=1000000,
n_jobs=-1, chunk_size=30000)
we.recording.set_probe(mesh_probe, in_place=True)
Setting 'return_scaled' to False
[10]:
CommonReferenceRecording: 30 channels - 1 segments - 10.0kHz - 990.848s
Plot spiking patterns
[11]:
day_length=[cont_trigger_all_all.shape[0]]
sorting_day_split(sorting, date_id_all, day_length, results_data_path,
sorting_save_name='firings_inlier')

<Figure size 640x480 with 0 Axes>
Plot ISI
[12]:
fig,ax = plt.subplots(int(ceil(sorting.unit_ids.shape[0]/4)),4,figsize=(10,10))
sw.plot_isi_distribution(sorting, window_ms=200.0, bin_ms=1.0,axes=ax)
[12]:
<spikeinterface.widgets._legacy_mpl_widgets.isidistribution.ISIDistributionWidget at 0x14d9f5dca040>

Plot units template
[13]:
we._template_cache={}
sorting_unit_show(we, recording_cmr, sorting, results_data_path,waveform_folder)
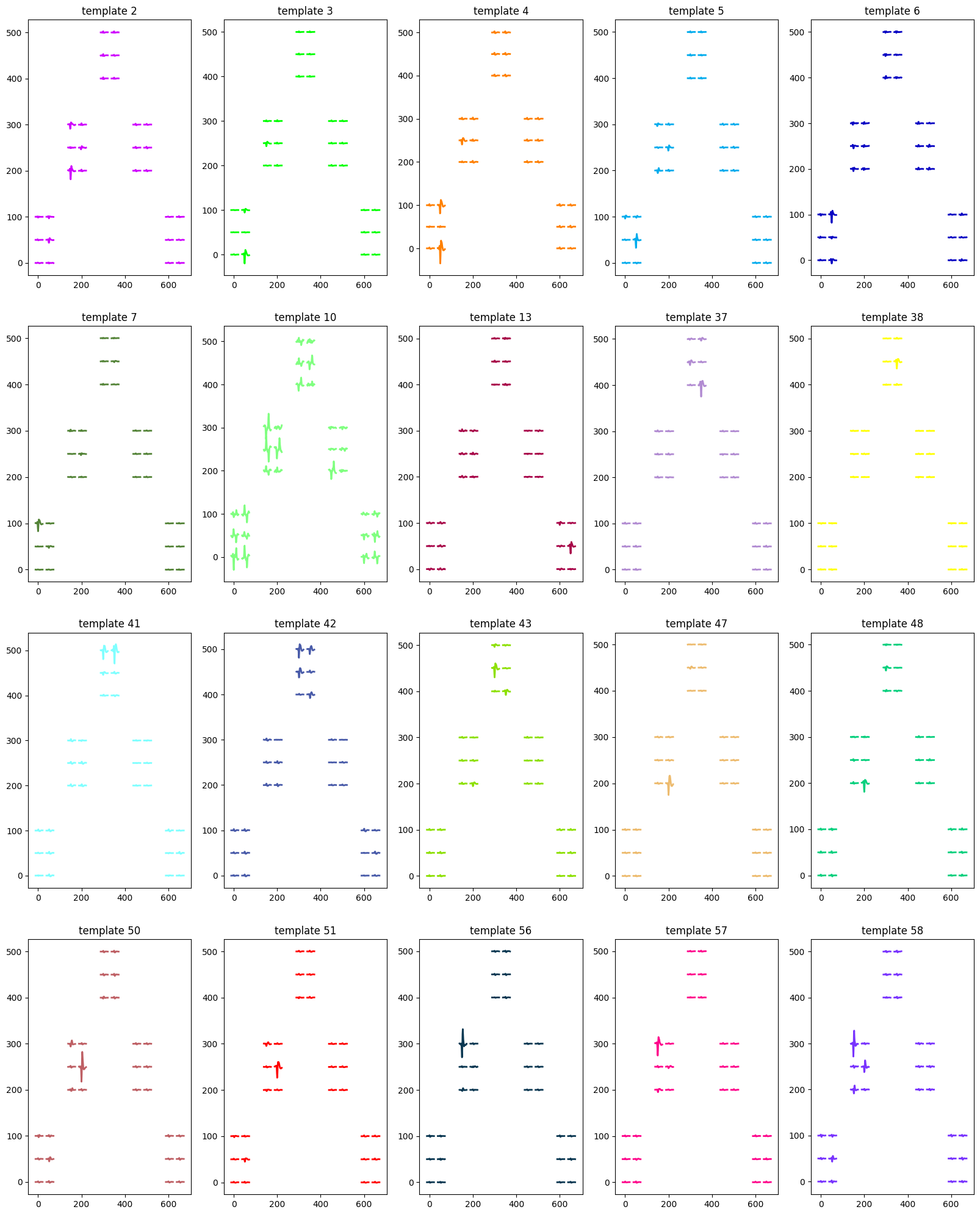
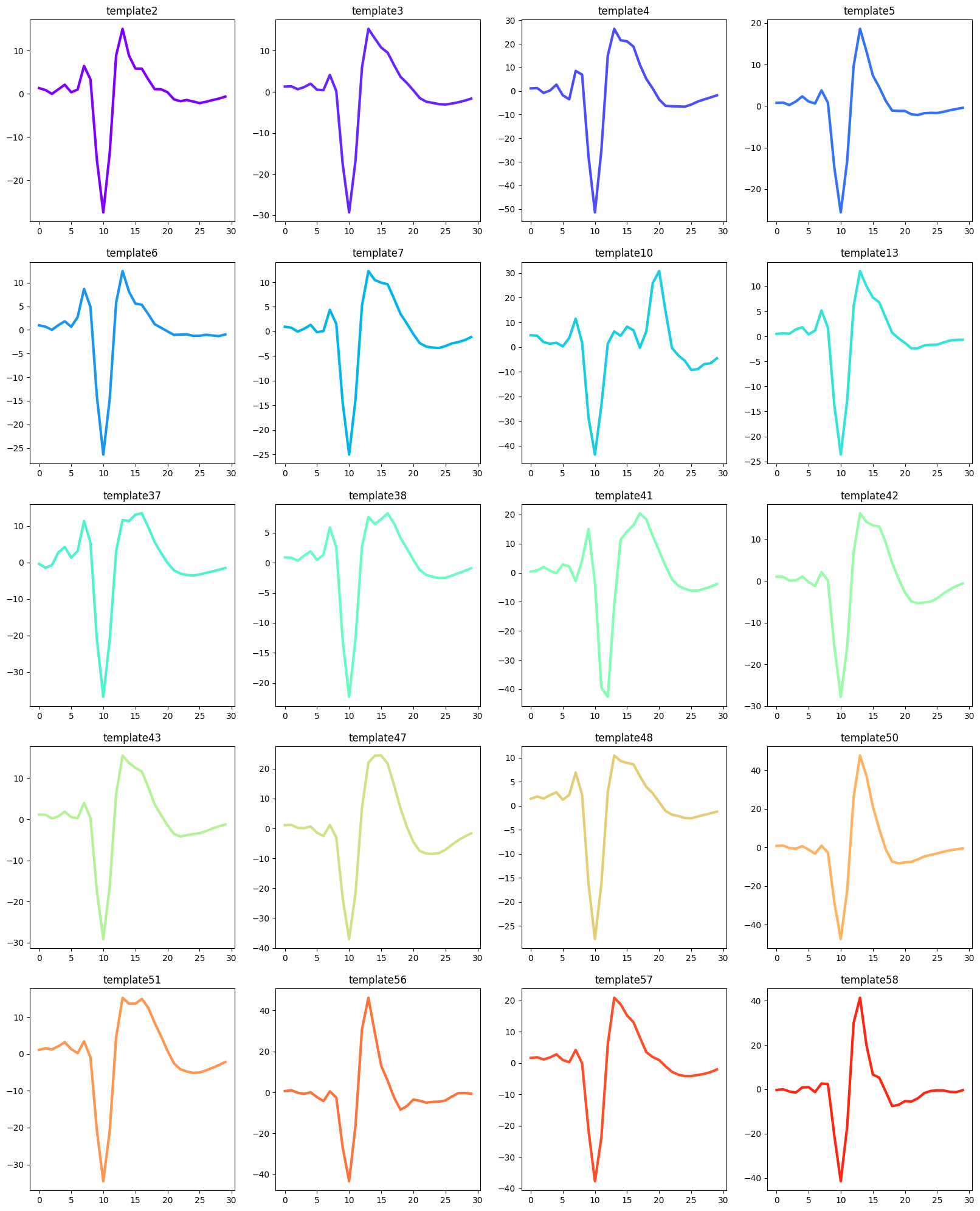
We can see that units identified from day 0310 [2,3,4,5,6,7,10,13,37,38,41,42,43,47,48,50,51,56,57,58] are sorted in day 0319 recordings.
The sorting result is saved in ./AutoSort_data/model_save/train_day0310_0/offline_result/0319/sorting/.